Seite 1 von 1
[Projekt] MemCP (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 17.01.2023, 13:47
von antisteo
Hey Leute,
ich stelle heute mal ein etwas ungewöhnliches Projekt vor: eine In-Memory-Datenbank (oder erst mal: Storage Engine) mit String- und Integer-Kompression, die später mal ein vollwertiger Nachbau eienr nicht näher benannten In-Memory-Datenbank eines ERP-Herstellers werden soll.
Kurz zum Abriss: Die DB ist besonders gut für analytische Queries geeignet, da man in einer spaltenbasierten Datenbank viel schneller so etwas wie Summen zusammenrechnen kann.
Dazu blogge ich auch auf launix.de. Der erste Blogbeitrag ist hier zu bestaunen:
https://launix.de/launix/on-designing-a ... in-golang/
https://launix.de/launix/how-to-balance ... workflows/
Re: [Projekt] cpdb (OpenSource HANA-Nachbau)
Verfasst: 17.01.2023, 21:09
von NytroX
Generell sehr interessant.
Bedarf an einer guten Storage-Lösung besteht auf jeden Fall in der Welt.
Spaltenbasierte Datenbanken sind gar nicht mal so gut; es ist quasi das ECS der Datenbanken :-)
Kann Vorteilhaft sein, wenn es deinem Usecase entspricht, aber man kommt sehr schnell an die Grenzen (z.B. wenn du große Tabellen filtern willst).
Spannend wären auf jeden Fall die TradeOffs, die du machen willst.
(d.h. sind die Daten bei einem Crash/Neustart weg, oder gibt es ein Backing-Store, und wie kommen die Daten performant da hin, usw. :-)
Mach am besten relativ früh Performance-Tests und vergleiche sie mit bestehenden DBs (z.B. einfach MariaDB, wenn >6GB Daten drin sind).
Hast du Erfahrung mit DB-Entwicklung?
Re: [Projekt] cpdb (OpenSource)
Verfasst: 17.01.2023, 23:26
von antisteo
Hallo NytroX,
ich habe selbst in den Forschungsteams rund um die Datenbank-Forschung gearbeitet und deshalb auch Erfahrung in der DB-Entwicklung.
Große Tabellen filtern geht bei Columnar Storages sogar ziemlich gut, da du im Filter-State nur die Spalten laden musst, nach denen auch gefiltert wird.
Allein die Kompressionsmöglichkeiten (Hey! Die Datenbank nimmt nur 50% des Platzes gegenüber der InnoDB ein. Damit bist du allein schon beim Full Scan um Größenordnungen schneller fertig, weil du weniger Speicherseiten einlesen musst)
Re: [Projekt] cpdb (OpenSource)
Verfasst: 18.01.2023, 00:41
von antisteo
Zweiter Blogbeitrag - diesmal über die Wahl von Scheme als Programmiersprache für die Query Plans in unserer In-Memory-Engine
https://launix.de/launix/designing-a-pr ... lgorithms/
Re: [Projekt] cpdb (OpenSource)
Verfasst: 18.01.2023, 17:25
von antisteo
Ein kleiner Beitrag, wie die DB eigentlich OLAP und OLTP-Workloads in einer einzigen Engine performant unterbringt:
https://launix.de/launix/how-to-balance ... workflows/
Re: [Projekt] cpdb (OpenSource)
Verfasst: 18.01.2023, 21:40
von antisteo
Re: [Projekt] cpdb (OpenSource)
Verfasst: 19.01.2023, 13:12
von antisteo
Im nächsten Beitrag gehts um den Aufbau von Indizes:
https://launix.de/launix/memory-efficie ... -storages/
Insgesamt habe ich eine Query-Zeit von 50µs zum Finden eines Strings in einer 10K-Einträge-Liste geschafft
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 21.01.2023, 10:50
von antisteo
In diesem Beitrag habe ich noch mal 40% des RAM-Verbrauchs eingespart, indem ich NULL-Werte mit weniger als 1 bit komprimiere:
https://launix.de/launix/on-compressing ... -storages/
Re: [Projekt] memcp (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 02.02.2023, 23:49
von antisteo
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 12.02.2023, 21:03
von antisteo
So, der SQL Parser ist Tail Recursive und nach etwas Eingewöhnung ziemlich straigt-forward zu schreiben. Inzwischen kann ich die ersten SQL Queries nach scheme übersetzen und somit per (eval) auswerten:
https://launix.de/launix/memcp-first-sq ... -executed/
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 15.02.2023, 17:07
von antisteo
Sequenzkompression brint einfach mal so 99% RAM-Ersparnis
https://launix.de/launix/sequence-compr ... tal-of-13/
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 16.03.2023, 10:31
von antisteo
Man kann 1 Bit in weniger Platz als 1 Bit abspeichern.
https://launix.de/launix/storing-a-bit- ... n-one-bit/
Einen ähnlichen Algorithmus nutzt auch ZIP/Deflate. Ich habe ihn mal aufgeschlüsselt inkl. Code-Beispielen. In einem 64-bit-Chunk bekomme ich ca. 200 Bits untergebracht gegeben eine unbalancierte Wahrscheinlichkeitsverteilung.
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 16.03.2023, 15:11
von Jonathan
Der Algorithmus sieht ganz interessant aus (ich kannte ihn glaube ich noch nicht und habe ihn jetzt auch eher überflogen), aber die Überschrift finde ich ein wenig, naja, albern. Zunächst einmal speicherst du ja nicht 1 Bit mit weniger als 1 Bit. Du speicherst eine große Anzahl an Bits in einer kleineren Anzahl an Bits. Und warum das irgendwie erstaunlich sein sollte erschließt sich mir überhaupt nicht, das ist halt die Definition von "Kompression" und das hat nun wirklich jeder schon mal gehört. In gewisser Weise wäre "Yet another compression algorithm" die bessere Überschrift gewesen. Das "Yet another" deshalb, weil im Artikel ja weder erwähnt wird, für was für Daten sich das besonders gut eignet, noch der Algorithmus mit irgendwelchen anderen verglichen wird.
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 16.03.2023, 15:21
von Krishty
Nutzt ZIP/Deflate nicht Huffmann Trees, während deins näher an Arithmetic Coding ist?
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 14.04.2023, 08:53
von antisteo
Krishty hat geschrieben: ↑16.03.2023, 15:21
Nutzt ZIP/Deflate nicht Huffmann Trees, während deins näher an Arithmetic Coding ist?
Du hast recht. Die Kompressionsrate von Arithmetic Coding kommt ja sogar noch näher ans Optimum heran als der Huffman Tree, der nur dann effizient ist, wenn die Wahrscheinlichkeit exakt einer 0,5-er-Potenz entspricht.
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 14.04.2023, 08:55
von antisteo
Es ist raus - Das Projekt steht jetzt auf Github und ab Montag gehen wir damit auf die Hannover-Messe
https://github.com/launix-de/memcp
Re: [Projekt] memcp (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 14.09.2023, 10:16
von antisteo
Die erste Anwendung existiert auf der Basis von MemCP:
Die Github Page ist jetzt auch gefinisht:
https://github.com/launix-de/memcp
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 14.12.2023, 17:21
von antisteo
Die MemCP hat's in die Weihnachtsvorlesung der Hochschule geschafft
Re: [Projekt] cpdb (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 16.12.2023, 23:15
von NytroX
Das traurige ist, finde ich, dass man immer denkt, dass sich die großen Datenbanken um sowas wie Komprimierung und Speichereffizienz Gedanken machen. Ich meine, was ist denn die Aufgabe einer Datenbank? Daten effizient zu speichern!
Und dann stellt man fest, dass alle klassischen Datenbanken einfach kacke sind.
Indizes sind vollständig im RAM oder gar nicht, es gibt keine ausgefeilten Algorithmen was wo wie gespeichert wird und warum, und Komprimierung funktioniert vorne und hinten nicht gescheit und macht alles nur langsamer.
Ganz zu schweigen davon, dass man immer den doppelten Platz der größten Tabelle (oder Tablespace) braucht, weil man sonst nicht defragmentieren/vacuumieren (oder wie sie es auch immer nennen) kann. Das kann quasi jedes Dateisystem besser.
Und wehe man will das aus unerfindlichen Gründen benötigte manuelle Housekeeping auf der Live-Datenbank machen, dann geht alles den Bach runter.
Und daran hat sich in den letzten 50 Jahren nichts geändert.
Re: [Projekt] MemCP (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 08.10.2024, 23:24
von antisteo
Ich nutze die MemCP ja auch in hardlife.io.
ein lesenswerter Beitrag:
https://www.memcp.org/wiki/Websockets_in_MemCP
Re: [Projekt] MemCP (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 02.11.2024, 20:36
von antisteo
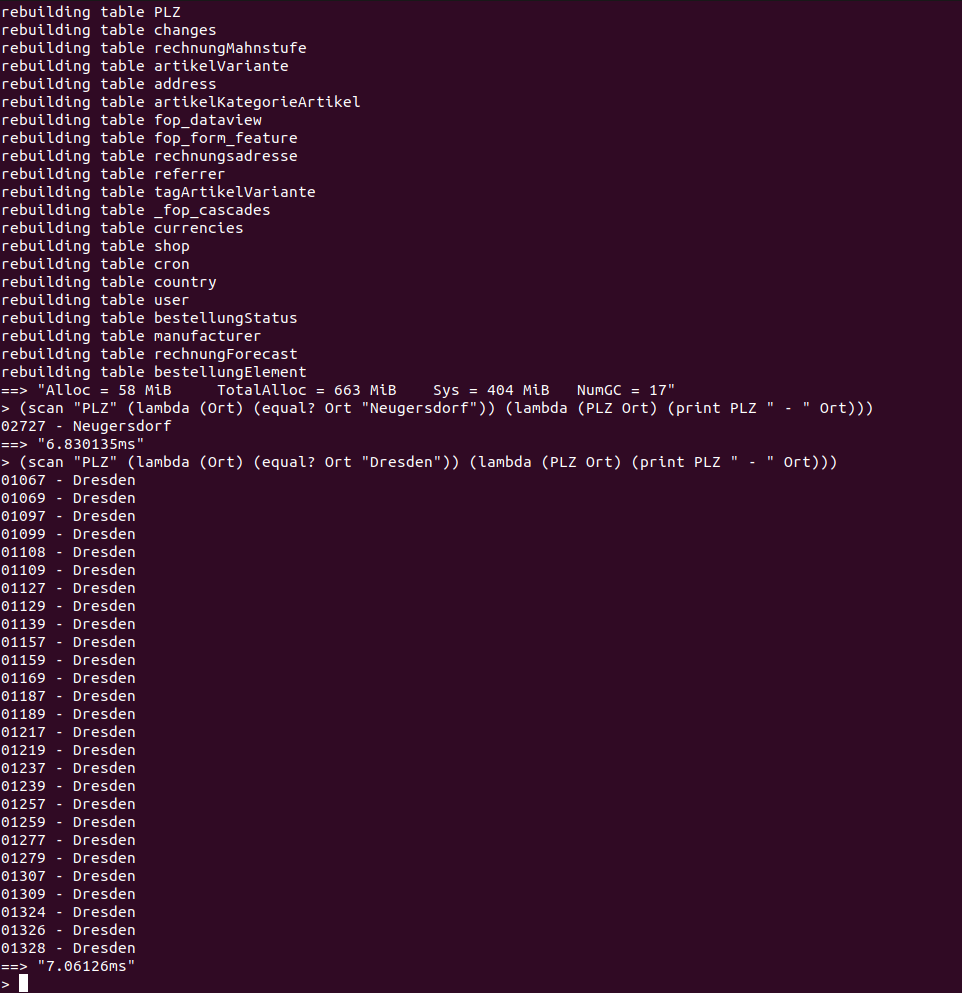
Wieder ein kleiner Meilenstein geschafft: jetzt werden Queries mit FROM (SELECT ...) AS t unterstützt, damit funktioniert meine Tabellenansicht schon mal. Implementiert habe ich das nicht über temporäre Tabellen, sondern über geschickte Umbenennung der Spalten, was ein Performance-Vorteil gegenüber MySQL ist. Für das komplette CRUD-Ensemble müssen jetzt noch die AUTO_INCREMENTs beachtet werden.
Ein kleines Seitenprojekt: Für das RDF-Frontend der Datenbank gibt es auch eine hübsche Template Engine, mit der man RDF-Daten layouten kann, indem man ähnlich PHP immer abwechselnd HTML-Schnipsel schreibt und dazwischen mit RDF-Queries (SPARQL) Daten aus der Metadatenbank holen kann. (Link:
https://github.com/launix-de/rdfop)
Re: [Projekt] MemCP (OpenSource In-Memory Spaltenbasierte Datenbank)
Verfasst: 03.11.2024, 15:06
von antisteo
So, AUTO_INCREMENT geht jetzt auch. Jetzt kann ich anfangen, erste Projekte auf das neue System rüberzuziehen.
In Benchmarks, die ich vor 6 Monaten gemacht habe, war ich ~10x schneller als MySQL bei 55 Mio Datensätzen Statistik-Queries